

Enlarge (credit: Nvidia)
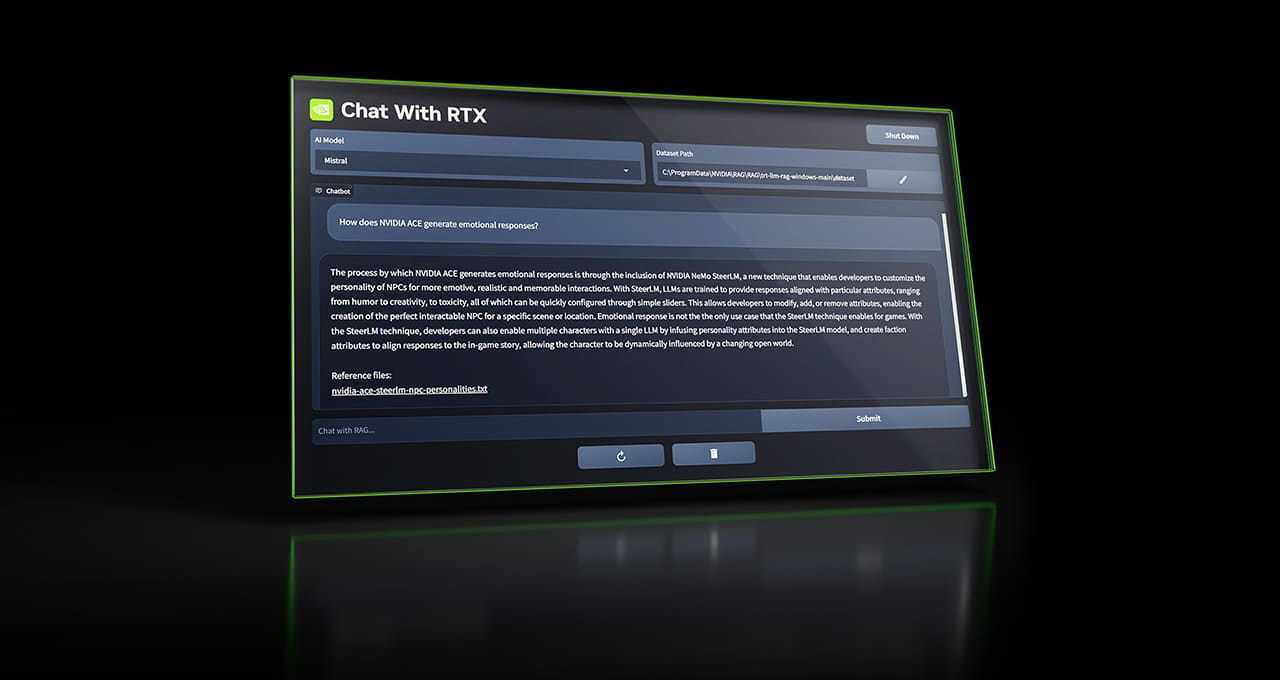
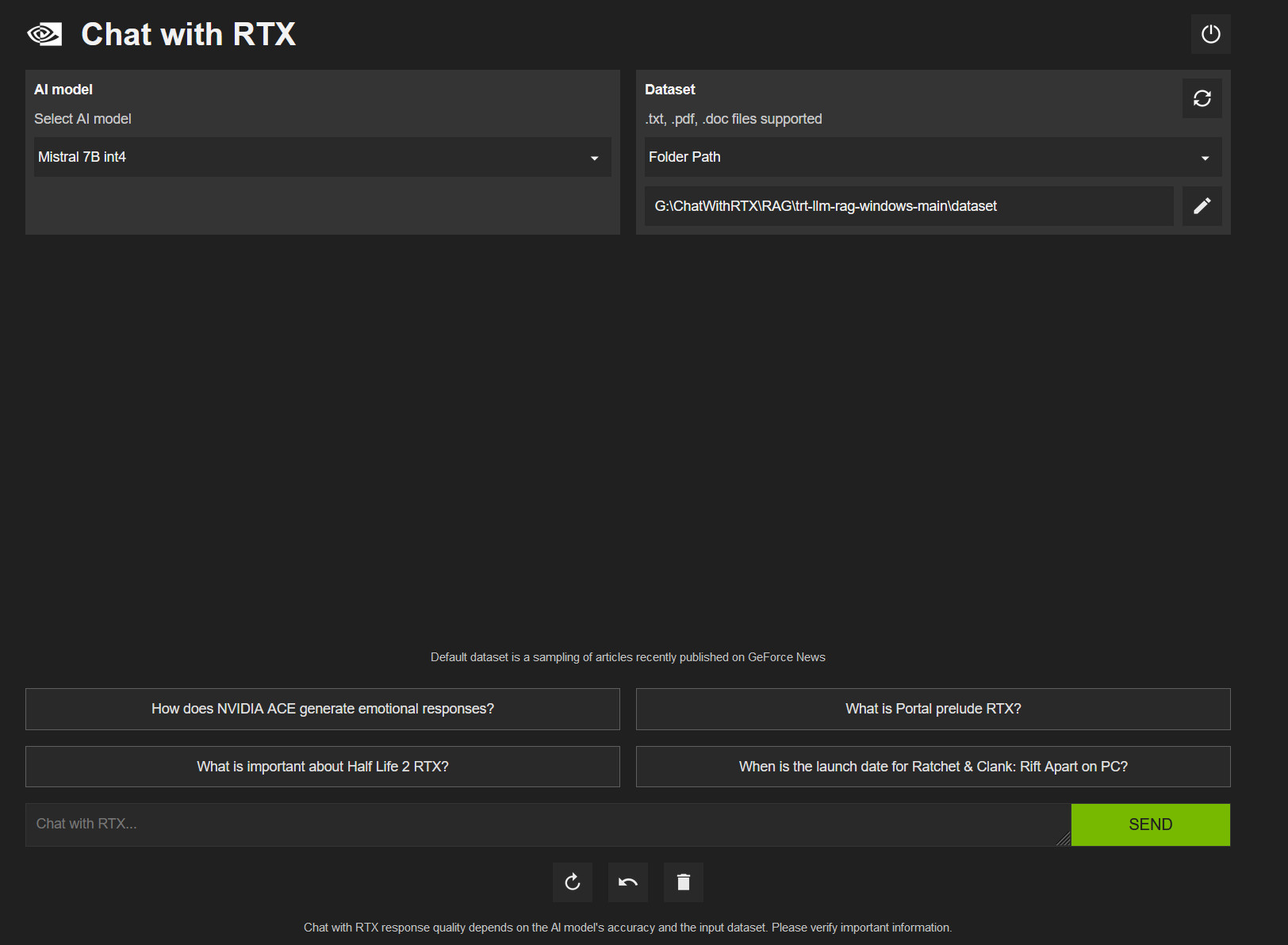
On Tuesday, Nvidia released Chat With RTX, a free personalized AI chatbot similar to ChatGPT that can run locally on a PC with an Nvidia RTX graphics card. It uses Mistral or Llama open-weights LLMs and can search through local files and answer questions about them.
Also, the application supports a variety of file formats, including .TXT, .PDF, .DOCX, and .XML. Users can direct the tool to browse specific folders, which Chat With RTX then scans to answer queries quickly. It even allows for the incorporation of information from YouTube videos and playlists, offering a way to include external content in its database of knowledge (in the form of embeddings) without requiring an Internet connection to process queries.
Rough around the edges
We downloaded and ran Chat With RTX to test it out. The download file is huge, at around 35 gigabytes, owing to the Mistral and Llama LLM weights files being included in the distribution. (“Weights” are the actual neural network files containing the values that represent data learned during the AI training process.) When installing, Chat With RTX downloads even more files, and it executes in a console window using Python with an interface that pops up in a web browser window.
Several times during our tests on an RTX 3060 with 12GB of VRAM, Chat With RTX crashed. Like open source LLM interfaces, Chat With RTX is a mess of layered dependencies, relying on Python, CUDA, TensorRT, and others. Nvidia hasn’t cracked the code for making the installation sleek and non-brittle. It’s a rough-around-the-edges solution that feels very much like an Nvidia skin over other local LLM interfaces (such as GPT4ALL). Even so, it’s notable that this capability is officially coming directly from Nvidia.
On the bright side (a massive bright side), local processing capability emphasizes user privacy, as sensitive data does not need to be transmitted to cloud-based services (such as with ChatGPT). Using Mistral 7B feels slightly less capable than ChatGPT-3.5 (the free version of ChatGPT), which is still remarkable for a local LLM running on a consumer GPU. It’s not a true ChatGPT replacement yet, and it can’t touch GPT-4 Turbo or Google Gemini Pro/Ultra in processing capability.
Nvidia GPU owners can download Chat With RTX for free on the Nvidia website.










{kind=link}
{kind=link}